Claude Is Now Writing Claude: The Architecture Behind It
More than 80% of the code going into Anthropic's production codebase is now authored by Claude. This is what that pipeline actually looks like — and where it still breaks.
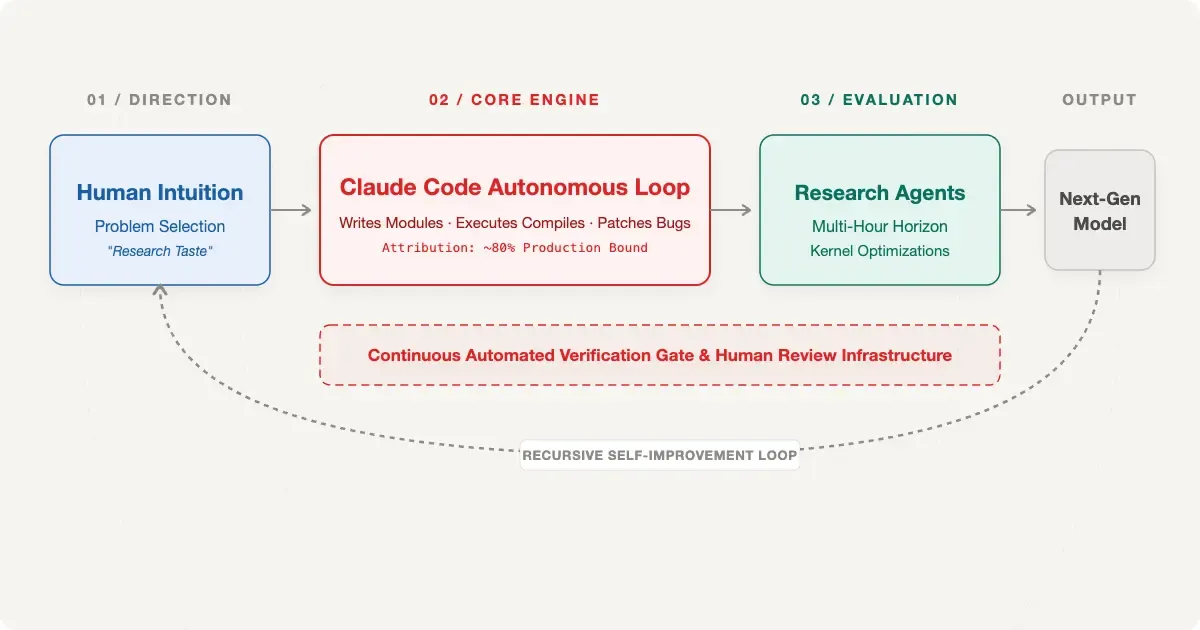
In February 2025, Claude Code shipped in a research preview. Before that, the share of AI-authored code merged into Anthropic's production codebase was in the low single digits. By May 2026, it crossed 80%. That's not drafts or suggestions, but is code that ships, with human review as the quality gate.
Anthropic published the internal data behind this in a piece called "When AI builds itself." The mechanics of how that loop works (and where it still can't close) are worth digging into.

The closed-loop runtime environment
To achieve an 80% production merge rate safely, the orchestration framework relies on a highly isolated, ephemeral execution layer rather than a simple text-generation interface. The autonomous pipeline enforces a strict isolation boundary between the model and production infrastructure:
- State Isolation via Micro-Containers: When a development session initializes, the orchestration layer provisions a secure, short-lived container (such as a gVisor-secured runtime environment). This container is strictly partitioned from core infrastructure, pre-configured with local repository clones and tight network firewalls.
- The Structured Tool-Call API: Claude operates within this environment via a deterministic schema of API endpoints rather than arbitrary shell access:
view_file_structureandsearch_grepfor workspace discovery.patch_target_fileutilizing Abstract Syntax Tree (AST) differential parsing instead of fragile regular expressions, preventing structural syntax breaks before compilation.execute_restricted_commandto trigger local unit testing, linters, and type checkers.
Consider this as a two-phase cycle. In the engineering phase, Claude writes code. In the research phase, Claude runs experiments. Humans supply the goals; Claude handles most of the method. Notice the catch word "most" here. Direction-setting is still the human's job, which is the exact gap the entire recursive self-improvement argument hinges on.
What 80% actually means
The 80% figure is a conservative number that comes from lines merged to production, attributed to Claude. Anthropic's own note is that the leadership estimate (90%+) is higher because it includes scripts and experimental code.
The more useful metric is output per engineer. Lines of code per engineer per day stayed flat for Anthropic's first four years (2021–2024). Then two inflection points hit. First in early 2025 when Claude started running code instead of just suggesting it. Second in 2026 when models began working autonomously across multi-hour time horizons. The result is 8× more code shipped per engineer per day in Q2 2026 versus the 2024 baseline.
Anthropic explicitly acknowledges the standard caveat that lines of code is a quantity measure, not a quality measure. But a 4× median self-reported productivity estimate from 130 employees across research teams is harder to dismiss as an artifact of metric selection. The number reflects faster execution on things that would have happened anyway — not just more code for its own sake.
The task horizon problem
METR tracks how long a model can work reliably on its own, a metric known as the "task horizon." That number has been doubling roughly every four months. In March 2024, Claude Opus 3 could handle tasks that take a human about four minutes. By early 2025, Claude Sonnet 3.7 was completing tasks that take about ninety minutes. By 2026, Claude Opus 4.6 was handling twelve-hour tasks.
The benchmark that makes this concrete is the training kernel optimization test. Anthropic runs it on every model release. They give Claude code that trains a small model and ask it to make that code run as fast as possible, subject to correctness. In May 2025, Claude Opus 4 averaged a 3× speedup. By April 2026, Claude Mythos Preview was hitting 52×. A skilled human researcher doing the same task would spend four to eight hours to reach 4×. That's the zone where Claude's execution quality has crossed into genuinely superhuman territory — not for arbitrary tasks, but for well-scoped optimization work with clear success metrics.
Success rate by task difficulty
Anthropic tracks Claude Code session success rate across four task types: trivial, routine, substantial, and open-ended. Success means Claude clearly completed the user's task without requiring corrections — judged by a separate Claude model after the fact.
On open-ended tasks, the rate was around 26% in November 2025. By May 2026, it hit 76%. A 50 percentage-point rise in six months on the hardest task category is the number to watch. It's what drives the reduction in "rate at which Anthropic staff correct, redirect, or take over mid-task from Claude" that Anthropic separately tracks.
Where it still breaks
The failure mode isn't bugs. The success rate data makes clear that Claude writes code that works. The gap is in what Anthropic calls "research taste" — the judgment about which experiments are worth running, which results to trust, and when an approach is a dead end.
Anthropic ran a specific test on this. They pulled real Claude Code sessions where researchers were working on open-ended investigative problems. In each session, they identified the moment where the human took a detour — pursued something that sent the investigation sideways before eventually recovering. Then they showed each Claude model only the pre-detour work and asked what it would do next. A judge Claude (which had seen how the whole session resolved) rated whether the AI or human suggestion was better.
In November 2025 with Opus 4.5, Claude beat the human choice 51% of the time — essentially noise. By April 2026 with Mythos Preview, that number was 64%. The trend is clear. But 64% means humans are still making the better call more than a third of the time on exactly the moments the test was designed to capture: realistic, hard situations where the right next step is genuinely non-obvious.
The automated research experiment
In April 2026, Anthropic published a demonstration of Claude running an open-ended safety research project end to end. The problem given was a weak supervision question: can a weaker model reliably supervise a stronger one? Claude-powered agents proposed hypotheses, ran tests, shared findings with parallel agents, and iterated. The task had a clear performance floor (the weak model on its own) and ceiling (the strong model trained on correct answers).
Two human researchers over about a week recovered roughly 23% of the gap between floor and ceiling. The agents recovered 97% over 800 cumulative compute hours and roughly $18,000 in API cost. The caveats are real — the result didn't transfer cleanly to production-scale models, humans set the problem and the scoring rubric, and agents designed every experiment within those constraints. But within those bounds, Claude handled the entire experimental design loop without human involvement in any individual step.
Amdahl's law is now the internal problem
Speeding up one part of a pipeline shifts the bottleneck. Anthropic is running into this directly. As Claude generates code faster, human code review has become a bottleneck. In response, they've added an automated Claude reviewer that reads every proposed change before it can merge, checking for bugs and security issues. Running a retrospective analysis on historical claude.ai incidents, they found this automated review would have caught roughly a third of the bugs that caused past production incidents — from code written by engineers Anthropic describes as among the best in the world at building these systems.
The same pressure is showing up in research. There are more ideas, initiatives, tools, and experimental simulations being generated than the organization has capacity to pursue. Claude's output has created an evaluation bottleneck. The rate at which a team can identify and fix those bottlenecks may be the most important organizational skill going forward — not productivity in the raw output sense, but throughput in the prioritization sense.
What closes the loop
The remaining gap between "Claude accelerates AI development" and "Claude autonomously develops AI" comes down to two things: training infrastructure access and research taste. On training infrastructure, Anthropic's framing is that this is more about access than capability — if Claude had the access, it could run the operations. On research taste, the 64% result suggests it's improving as a learnable capability rather than a fixed ceiling.
Anthropic's own position is that full recursive self-improvement — where Claude can design, build, and train its own successors without meaningful human involvement — is not here yet, and not inevitable. But the internal evidence they're publishing suggests every sub-capability that would be required is measurably improving. The question they're raising publicly is whether the verification and coordination infrastructure to make that safe will keep pace with the capability itself.
For now, the answer to "Claude is writing Claude" is: mostly yes, for the engineering. Not yet, for the research direction. That gap is closing at a rate that makes both claims potentially equivalent within a few years.
Source data: Anthropic Institute, When AI builds itself (June 2026). Internal Anthropic metrics on code attribution, engineer productivity, METR task horizon benchmarks, and the research taste evaluation (n=129 sessions).

