Why Your Vision Transformer Dumps Garbage Into Random Pixels
Your transformer dumps computational garbage into random pixels because math forces it to. Register tokens solve this by providing proper workspace for the model's messy calculations.
A comprehensive analysis published yesterday shows how the research community has made significant progress understanding attention sink artifacts since they were discovered in 2024[1]. The breakthrough matters because these weird behavior patterns have been quietly degrading model performance in production systems without most engineers realizing it.
Vision transformers and large language models keep making the same mistake. They suffer from a persistent anomaly where high-norm spikes emerge across both supervised and self-supervised training regimes, with the original DINO being a notable exception[1]. These spikes create noise that makes the models worse at seeing and understanding images, especially in situations where there's not much useful information to work with.
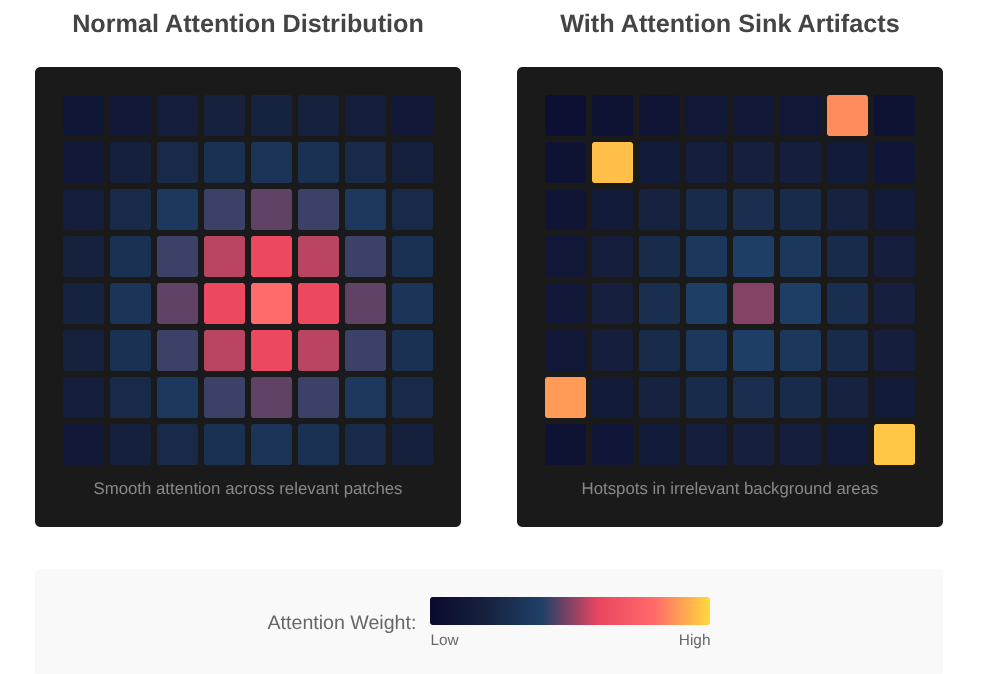
The root of the problem is surprisingly simple. The artifacts are a byproduct of the Softmax function, which forces attention weights to sum to 1, and even when a query token has no meaningful relationship with any key token, the SoftMax operation forces it to distribute its attention mass, which often gets dumped into specific low-information background tokens that then become high-norm sinks[1].
So the model finds a workaround. Think of it like using scratch paper when doing math in your head. The model recycles useless parts of images as temporary storage. Smart move, but it creates a mess that shows up as weird artifacts in attention maps and feature visualizations.
The fix researchers validated is beautifully straightforward. Adding registers to models like DINOv2 prevents artifacts from appearing in patch tokens[1]. These extra tokens work like designated parking spots for the model's temporary work. Instead of scribbling calculations all over the actual image data, the model gets clean workspace tokens to use however it needs.
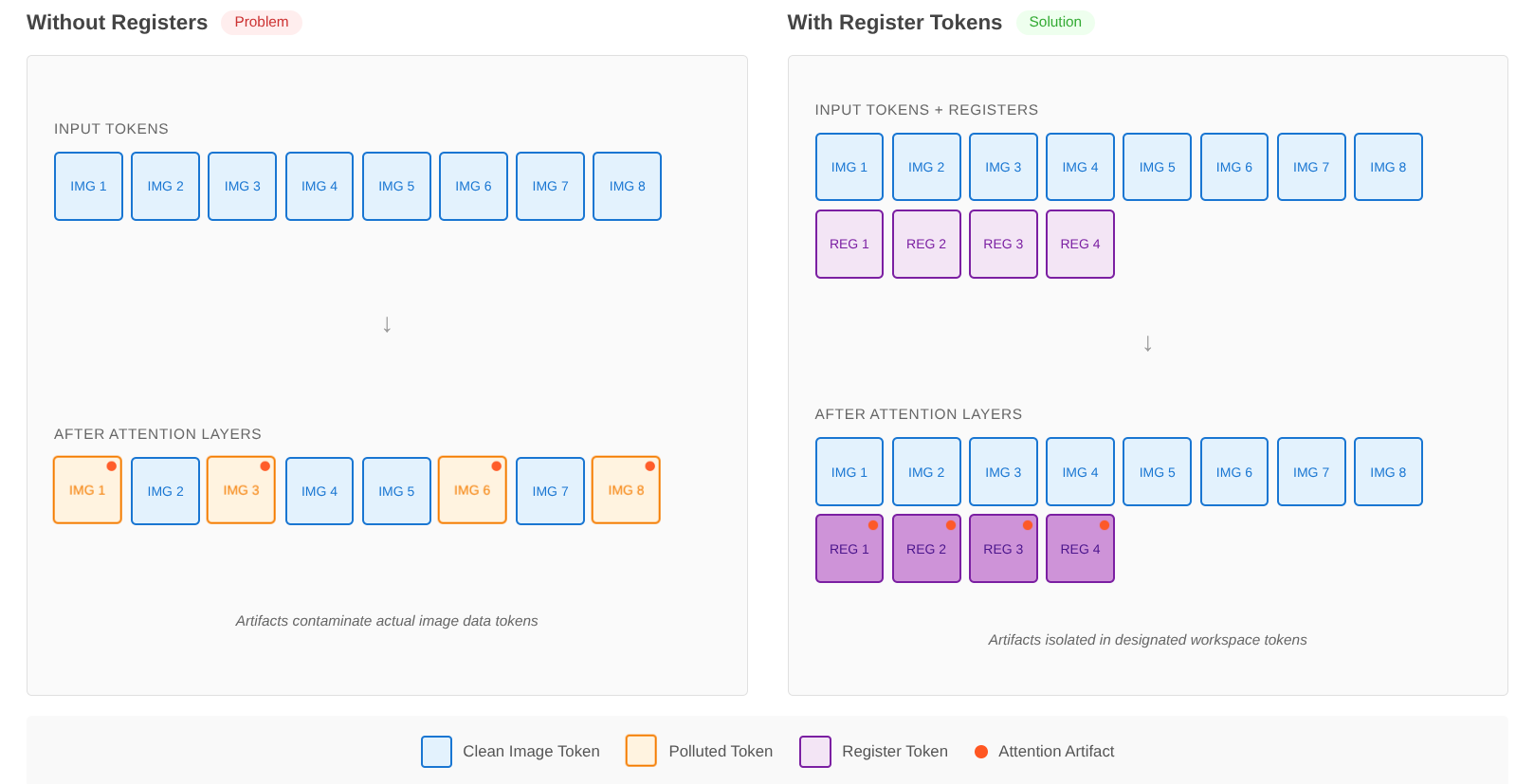
The latest solutions require little to no retraining and introduce zero additional test-time latency[1]. What makes this breakthrough particularly useful is you might not even need to retrain your models. Recent work demonstrates test-time interventions without any retraining by detecting the few register neurons that drive the outliers and redirecting their activations into a single untrained token appended at inference.
One of the NeurIPS 2025 papers proposes a general solution to these attention sink artifacts which modifies the self-attention transformer architecture, and this modified architecture is already being incorporated into the latest Qwen model, Qwen3-Next[1].
The results speak for themselves across multiple model families. Performance improvements show up in dense prediction tasks like object detection and segmentation, where these artifacts historically caused the biggest problems.
From the Editor's Desk
What strikes about this development is the timeline. Since the distant past of 2024, when high-norm artifacts of ViTs and attention sinks of LLMs were discovered, the research community has discovered many solutions[1]. That's less than two years from discovery to production deployment in major models like Qwen3.
The progression here matters. First, people spotted strange patterns in attention maps. Then came proposals to retrain everything with extra tokens built in. Now we have methods that work at test time without touching the original model weights. That path from expensive architectural overhauls to cheap runtime fixes is exactly how research becomes practical engineering.
This could be a sign that we are moving away from single elegant solutions, like repeated self-attention modules, and more towards a collection of hacks or heuristics that gets the best performance, which could be similar to the brain, with its wide variety of types of neurons, neurotransmitters, and neuroreceptors[1].
For anyone running vision transformers in production and seeing messy attention maps or poor performance on tasks like segmentation, test-time registers offer a zero-cost intervention worth trying today. For researchers, this raises a bigger question about how many other supposed bugs are actually optimal solutions to constraints we haven't fully mapped out yet.
Not understanding these downfalls could cause your project to substantially underperform or fail[1]. The DINOv2 example is telling. Models with and without registers show similar ImageNet classification scores, which might lead you to skip registers entirely. But use that same model for object detection without registers and your performance tanks.
Sometimes the best fix isn't stopping the behavior. It's understanding why it happens and giving the model better tools to do what it needs to do.
References
- [1]Glitches in the Attention Matrix | Towards Data Science
- Vision Transformers Need Registers | OpenReview
- Vision Transformers Don't Need Trained Registers
- When Attention Sink Emerges in Language Models: An Empirical View | ICLR 2025
- Gated Attention: Solving the Hidden Bottlenecks in Transformer Attention | Medium
- Efficient Streaming Language Models with Attention Sinks
- Attention Sink Phenomenon in Transformers | Emergent Mind
- Let the Chaos Sink In | Carnot Research