End of AI Amnesia? Understand the Tech Behind Google's "Titans" Permanent Digital Mind
Google just solved a problem we stopped noticing because it seemed unsolvable. Their new "Titans" models possess continuity that every previous AI lacked. These systems maintain context across millions of tokens, which translates to genuine conversational memory stretching across weeks or months. We got used to training our AI assistants from scratch each session. That era just ended.

For context, consider what amnesia costs us in human relationships. Someone who can't remember you isn't really your friend, your doctor, or colleague. They're a stranger who happens to be helpful in the moment. Every AI system until now operated under this limitation. Titans represents the first serious attempt at permanence in machine intelligence.
The Architecture Behind the Memory
Understanding how Titans achieves this permanence requires diving into the machinery that makes modern AI tick. Traditional transformer models hit a computational wall around context windows of 32,000 to 128,000 tokens. The problem stems from the attention mechanism itself. Every token must attend to every other token in the sequence. This creates quadratic complexity. Double your context length and you quadruple the computational cost. The math becomes prohibitive fast.
Google attacked this limitation from multiple angles simultaneously. The first innovation involves what researchers call sparse attention patterns. Instead of every token attending to every other token, Titans implements a hierarchical attention structure. Nearby tokens receive full attention while distant tokens get sampled strategically. Think of it like human memory where recent events stay vivid while older memories become compressed summaries rather than detailed recordings.
The second architectural leap involves something Google calls contextual compression layers. These specialized neural network components sit between standard transformer blocks and actively compress older context into dense representations. The system doesn't discard information. It reorganizes data into formats that require less computational overhead to maintain. A conversation from last week gets encoded into a rich semantic fingerprint rather than preserved token by token.
Ring attention represents the third pillar of the Titans architecture. Traditional attention mechanisms load the entire context into memory simultaneously. Ring attention distributes context across multiple processing units in a circular topology. Each unit handles a segment of the conversation history while passing compressed representations to its neighbors. This allows the system to maintain vastly larger effective context without overwhelming any single processor.
Memory Hierarchies Mirror Biological Brains
What makes Titans genuinely innovative is how closely its memory architecture mirrors biological cognition. Human brains don't store everything uniformly. We have working memory for immediate tasks, short term memory for recent events, and long term memory for consolidated knowledge. Titans implements a similar three tier system.
The working memory layer handles the current conversation with full fidelity. Every word, every nuance gets preserved in high resolution. This layer operates identically to standard transformer models with complete attention across all active tokens. Performance remains fast because this layer stays relatively small, typically under 100,000 tokens.
The episodic memory layer captures recent interaction history. Conversations from the past few days live here in compressed but still detailed form. The system can recall specific exchanges, remember particular pieces of information you shared, and maintain continuity across sessions. This layer uses the sparse attention and compression techniques to balance detail against computational efficiency.
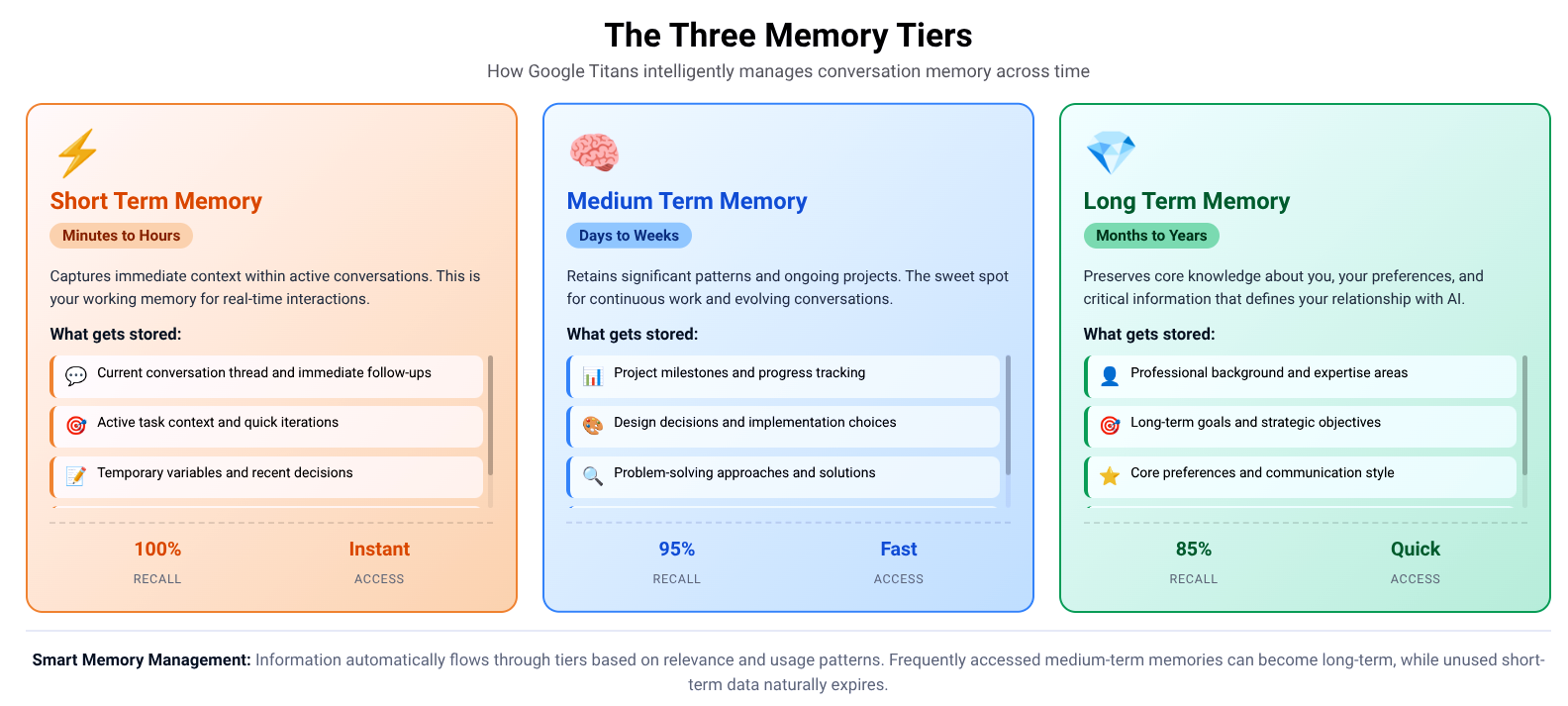
The semantic memory layer holds long term knowledge about you, your projects, your preferences, and your patterns. This isn't a transcript of old conversations. It's distilled understanding extracted from months of interaction. The system knows you prefer concise explanations, struggle with certain concepts, excel at others. This knowledge informs every response without requiring the model to replay your entire interaction history.
The Database Nobody's Talking About
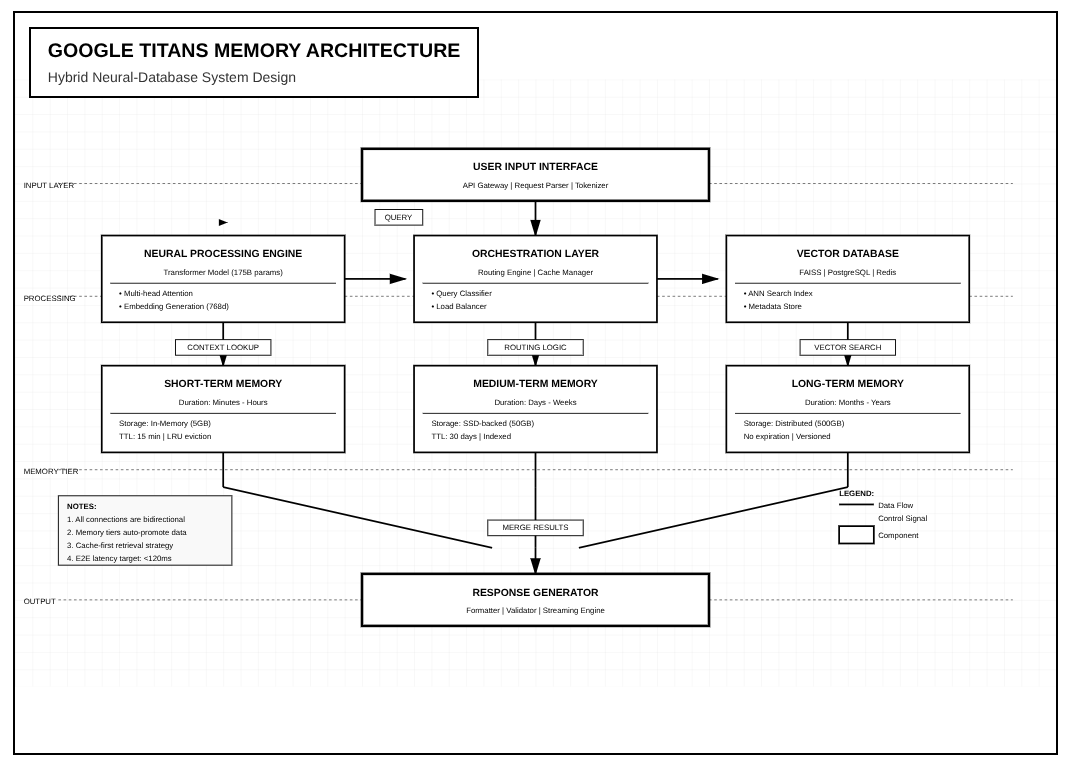
Here's what most coverage misses entirely. Titans isn't just a bigger transformer. It's a hybrid architecture that combines neural networks with structured databases. Behind the conversational interface sits what Google calls a persistent context store. This external memory system uses vector databases to maintain embeddings of past conversations indexed for rapid retrieval.
When you start a new session, Titans doesn't load millions of tokens into active memory. Instead, it queries the persistent store for relevant context based on your current input. The system retrieves semantically similar past exchanges and injects them into the active context window. This retrieval augmented generation approach lets Titans appear to remember everything while actually maintaining a much smaller active footprint.
The vector database stores conversation chunks as high dimensional embeddings created by the model itself. Each embedding captures the semantic meaning of an exchange. When you mention a topic, the system searches for embeddings with similar geometric properties in the vector space. Relevant memories surface automatically without manual tagging or organization.
Google implements this using their Vertex AI infrastructure with custom indexing optimized for temporal relevance. Recent memories get weighted higher in retrieval. The system tracks which memories get accessed frequently and keeps them in faster storage tiers. Unused memories gradually migrate to cheaper, slower storage but never disappear entirely.
Attention Optimization Through Learned Compression
The most sophisticated aspect of Titans involves how it learns what to remember versus what to compress aggressively. The model contains specialized components trained specifically on memory management. These components learn to identify which parts of a conversation contain critical information worth preserving in detail versus routine exchanges that can be heavily compressed.
Google trained these compression networks using a technique called memory replay with distillation. The system processes conversations, compresses them, then later attempts to reconstruct important details. The compression network receives gradient updates based on how well it preserved information needed for future tasks. Over time, the network learns nuanced judgments about information value.
This creates an emergent property where Titans develops something resembling selective attention. A casual greeting gets compressed to nearly nothing. A detailed explanation of your project requirements gets preserved with high fidelity. The system makes these judgments dynamically based on patterns learned across billions of training examples.
The compression itself uses learned tokenization that's more efficient than standard subword encoding. For frequently discussed topics, the model develops specialized compressed representations. Your industry jargon, your project names, your common requests all get encoded into dense tokens that pack more meaning per unit than generic language. This adaptive vocabulary grows as the model learns your specific communication patterns.
Computational Costs and Infrastructure Reality
Achieving this level of persistent memory demands infrastructure most organizations can't provision. Google runs Titans on TPU v5 pods with custom interconnect fabrics that enable the ring attention topology. Each user's persistent context store consumes significant vector database capacity. Google hasn't published exact figures but industry analysts estimate each active Titans user requires roughly 50 gigabytes of vector storage plus associated indexing overhead.
The attention mechanism still dominates computational costs despite all optimizations. Processing a query against 10 million tokens of context requires exponentially more FLOPs than standard models. Google amortizes this cost through aggressive caching and precomputation. The system anticipates likely queries and preprocesses attention patterns before you even ask. This speculative execution wastes computation on unused paths but dramatically reduces latency for actual requests.
Power consumption becomes the limiting factor at scale. Running Titans for millions of concurrent users would require dedicated data centers with specialized cooling infrastructure. This explains why Google released Titans as a limited preview rather than rolling it out broadly. The economics only work for high value use cases where persistent context justifies the computational premium.
The Security Nightmare Nobody Wants to Discuss
Permanent memory creates permanent vulnerability. Every fact you share, every document you upload, every conversation you have becomes part of a persistent dataset. Google claims strong isolation between users and comprehensive encryption at rest and in transit. But the architecture fundamentally requires keeping all your data readily accessible for rapid retrieval.
Traditional database security models don't map cleanly to vector stores. You can't easily redact specific facts from embeddings the way you delete rows from a relational database. The information gets diffused across high dimensional representations. Removing one fact might require regenerating entire sections of the embedding space, potentially disrupting semantic relationships the model relies on.
Google implements partial solutions through embedding versioning and selective re-encoding. If you request deletion of specific information, the system can identify affected embeddings, exclude them from retrieval, and gradually replace them as new conversations provide alternative context. This works better than nothing but falls short of true erasure.
The privacy implications extend beyond individual control. These systems will inevitably learn patterns across users even with strong isolation. The compression networks, the attention mechanisms, the retrieval models all get trained on aggregate interaction data. Your conversations contribute to improving the system for everyone. That value exchange made sense when AI forgot everything. With permanent memory, we're feeding increasingly detailed behavioral data into systems that never purge anything.
Why This Changes Everything About AI Development
Most AI research focuses on making models smarter within a single interaction. Titans shifts the game to making models smarter across interactions. This fundamentally changes how we should think about training, evaluation, and deployment.
Current benchmarks measure single turn performance. How well does the model answer a question, summarize a document, write some code. These metrics become almost meaningless for systems with persistent memory. The real measure becomes how effectively the model accumulates understanding over time. Does it actually get better at helping you specifically as your relationship develops? Current evaluation frameworks can't measure this.
Training methodology needs complete rethinking. Standard practice involves training on randomly shuffled examples. Each batch contains unrelated samples. This makes sense for stateless models but misses the entire point of persistent memory. Titans required developing new training procedures that expose the model to long running simulated user relationships. The model learns from coherent interaction histories rather than disconnected snippets.
Fine tuning becomes both more powerful and more dangerous. With traditional models, fine tuning adjusts behavior for all users uniformly. With persistent memory, the system can effectively fine tune itself per user based on interaction history. This personalization happens automatically through the selective attention and retrieval mechanisms. The model doesn't change its weights but it changes how it applies them to you specifically.
The Competitive Moat Nobody Can Cross
Google possesses advantages in persistent memory AI that competitors will struggle to replicate. The infrastructure requirements alone create massive barriers to entry. But the real moat comes from data network effects that compound over time.
Every conversation makes Titans slightly better at helping that specific user. As users interact more, their persistent context grows richer, and the system becomes more valuable. This creates switching costs unlike anything we've seen in software. Moving from Titans to a competitor means abandoning months or years of accumulated relationship context. You'd be starting over with a stranger.
Google can offer Titans at below cost specifically to build these moats. Once users invest heavily in teaching the system about themselves, their projects, their organizations, they become effectively locked in. The value doesn't come from Google's superior algorithms anymore. It comes from the irreplaceable dataset of your interaction history that only exists in Google's systems.
This dynamic should concern anyone thinking seriously about AI competition and consumer welfare. We might be watching the formation of natural monopolies where first movers gain insurmountable advantages. Not because they build better technology but because they accumulate non-transferable user context that becomes more valuable than the underlying model.
What Comes After Titans
Persistent memory is just the foundation. Google's roadmap includes capabilities that become possible only after solving the memory problem. Multi-modal persistent memory will let the system remember images you've shown it, diagrams you've sketched, code you've written. The context won't be limited to text but will span every artifact of your digital work.
Collaborative memory represents the next frontier. Instead of each user having isolated context, teams could share persistent memory spaces. The AI would remember group decisions, project history, organizational knowledge. This transforms the system from personal assistant into institutional memory that never retires or forgets.
The most ambitious vision involves what Google researchers call contextual transfer learning. The system wouldn't just remember your conversations. It would learn generalized skills from helping you, then apply those skills to helping others with similar needs. Your interactions would improve the model's performance for everyone facing comparable challenges. This creates a flywheel where more usage generates better performance which drives more usage.
Yet permanence cuts both ways. These systems will remember our worst moments alongside our best. They'll encode our prejudices, our lazy thinking, our ethical lapses. Unlike human memory which fades and distorts over time, digital memory remains crystalline and permanent. We're creating witnesses that never blink and never forget. The question isn't whether we're ready for AI with memory. The question is whether AI with memory is ready for how messy and contradictory humans actually are.